This document explains how to enable Abaqus Checkpointing & Restart (C&R) with the Slurm Workload Manager. This feature can be used to minimise the impact of a hardware issue by restarting the job from the last checkpoint.

Additionally, native C&R can also be used to take advantage of Slurm job preemption based on a re-queueing mechanism. In general, the C&R relies on a fast shared filesystem, since extensive use of C&R could introduce an unreasonable overhead due to slow filesystem operations. The following software packages were used on RHEL 6.3 operating system:
- Slurm Workload Manager 14.11
- Abaqus 6.13-2
- IBM Platform MPI 8.3
About Abaqus
The Abaqus Unified FEA product suite offers powerful and complete solutions for both routine and sophisticated engineering problems covering a vast spectrum of industrial applications. In the automotive industry, engineering work groups are able to consider full vehicle loads, dynamic vibration, multibody systems, impacts/crashes, nonlinear statics, thermal coupling, and acoustic-structural coupling using a common model data structure and integrated solver technology. Best-in-class companies are taking advantage of Abaqus Unified FEA to consolidate their processes and tools, reduce costs and inefficiencies, and gain a competitive advantage.
Official website: http://www.3ds.com/products-services/simulia/products/abaqus/
Disclaimer: The article uses optimization configuration, specific to the particular computational environment. In order to produce an optimised package for a different combination of hardware, software and parallelisation environments, some changes may be required.
Implement restart options in the input file
When running an analysis with Abaqus, you are allowed to write the model definition and state the files required for restart. Scenarios for using the restart capability are as follows:
- Changing an analysis: After viewing results from the previous analysis, you might need to change the load history data from an intermediate point. In such case, Abaqus lets you to restart the analysis from that point.
- Continuing with additional steps: Sometimes, having viewed the results of a successful analysis, you might decide to append steps to the load history.
- Continuing an interrupted run: The Abaqus restart analysis capability allows the interrupted analysis to be completed as originally defined.
This article covers the last scenario mentioned above: continuing an interrupted run. Abaqus allows using restart files in order to continue the analysis from a specific step in a previous analysis. By default, Abaqus is not going to dump any restart information for an Abaqus/Standard or an Abaqus/CFD analysis into your filesystem. In the case of Abaqus/Explicit analysis, Abaqus will write only at the beginning and end of each step.
Abaqus allows to specifying the frequency at which software will write data to the restart files, but unfortunately, how the analysis is restarted depends on each analysis product.
- For an Abaqus/Standard step, it is possible to choose whether the output is written at the exact time interval (or at the closest value). Restart at exact time intervals is available only for steps with an automatic time incrementation.
- For Abaqus/Standard and Abaqus/CFD, it is possible to request the frequency in increments or in time intervals.
- For an Abaqus/Explicit analysis, it is possible to specify the number of time intervals at which Abaqus writes data to the restart files.
- For an Abaqus/Explicit step, it is possible to choose whether the output is written at the exact time interval (or at the closest value).
- For an Abaqus/Standard or an Abaqus/Explicit analysis, it is possible to request that data written to the restart files overlay data from the previous increment. This option will retain the information from the last increment, thus avoiding the need to keep unnecessary files and minimizing the shared filesystem usage. Note that by default, Abaqus does not overlay data.
The Abaqus restartjoin option allows extracting data from the output database created by a restart analysis and appending the data to a second output database. This operation may depend on the size of your model, and based on the initial tests, it does not seem like an overly expensive filesystem operation. This operation seems to be quite sensitive and sometimes it is not possible to generate the second output database due to a corrupted database. For that reason, it could be a good practice to keep a backup of the last two increments.
Again, how an analysis is restarted will depend on the analysis products.
- Recover option: only available for Abaqus/Explicit.
- Restart option: used to start the analysis using data from a previous analysis of a specified model.
Case Abaqus/Standard
The following setup will be valid for workflows based on reliability. However, in addition to that, thanks to the Slurm re-queueing mechanism, one can take advantage of job preemption. This will provide clear benefits in terms of the suspension mechanism. For example, the ability to:
- Avoid stealing unnecessary (shared) Abaqus tokens for idle (suspended) jobs.
- Run long-term jobs minimising the impact of potential hardware failure.
- Divide long-term jobs into several incremental runs of the same analysis.
- Migrate jobs to more suitable resources.
To request that restart data be written for analysis, your Abaqus input file must contain the following line after the line **OUTPUT REQUESTS. Note that “frequency=1” means “write at every increment”. If this is too frequent (i.e., excessive file output is causing too much delay), increase the number.
*Restart, write, overlay, frequency=1Workflow based re-queueing mechanism
The following submit script allows submit a job in Slurm Workload Manager. This script will allow running the job for at least one hour per run and the job will be restarted as needed. Please note that you only need to worry about the standard job definition parameters – the job name, the input file and the frequency – that you have setup in your input files. This script assumes that you have already defined a temporary cluster file system capable of digesting the intensive file system operations. In this case, $CHK_DIR is created in the job prolog with the proper ACLs, and the environment variable is defined in the task prolog.
The Slurm option –time-min is key to ensure progress in the analysis. It defines the minimum time limit on the job allocation. In this case, this value should be an upper limit for the time required to compute the checkpointtable cycle(s), in addition to the time required to dump the information into the shared filesystem. An underestimated value could potentially allow Slurm to kill the job prematurely.
#!/bin/bash
#SBATCH -J Abaqus_JOB-CHECKPOINT
#SBATCH -A nesi99999
#SBATCH --time=10:00:00
#SBATCH --ntasks=4
#SBATCH --mem-per-cpu=2048
#SBATCH --open-mode=append
#SBATCH -p requeue
#SBATCH --time-min=01:00:00
### Load the Environment
module load ABAQUS/6.13.2-linux-x86_64
source /share/SubmitScripts/slurm/slurm_setup_abaqus-env.sh
### In many cases you only need to worry about the following two lines
JOBNAME=job-checkpoint
INPUT=job-checkpoint
FREQ=1
### Copying files to CHK folder (global scratch file system)
if ! [ -d $CHK_DIR/$JOBNAME ]; then
mkdir $CHK_DIR/$JOBNAME
cp $INPUT.inp $CHK_DIR/$JOBNAME/
fi
cd $CHK_DIR/$JOBNAME
if [[ -f Res_$INPUT.sta ]]; then
rm -f *.lck
abaqus restartjoin originalodb=$INPUT restartodb=Res_$INPUT history
for i in res mdl stt prt sim sta com cid 023 dat msg
do
mv Res_$INPUT.$i $INPUT.$i
done
fi
### Run the Parallel Program
if [[ -f $INPUT.sta ]] || [[ -f Res_$INPUT.sta ]]; then
echo "*Heading" > Res_$INPUT.inp
cat $INPUT.sta | gawk -v freq=$FREQ '{if($3 !~/U/){print "*Restart, read, step="$1",inc="$2", write, overlay, frequency="freq}}' | tail -1 >> Res_$INPUT.inp
abaqus job=Res_$JOBNAME input=Res_$INPUT.inp oldjob=$JOBNAME cpus=$SLURM_NTASKS -verbose 3 standard_parallel=all mp_mode=mpi interactive
else
abaqus job=$JOBNAME input=$INPUT.inp cpus=$SLURM_NTASKS -verbose 3 standard_parallel=all mp_mode=mpi interactive
fi
### Transfer output files back to the project folder
cp *.dat $SLURM_SUBMIT_DIR/
cp *.msg $SLURM_SUBMIT_DIR/
cp *.sta $SLURM_SUBMIT_DIR/
Evaluate the impact on the cluster file system and analysis runtime
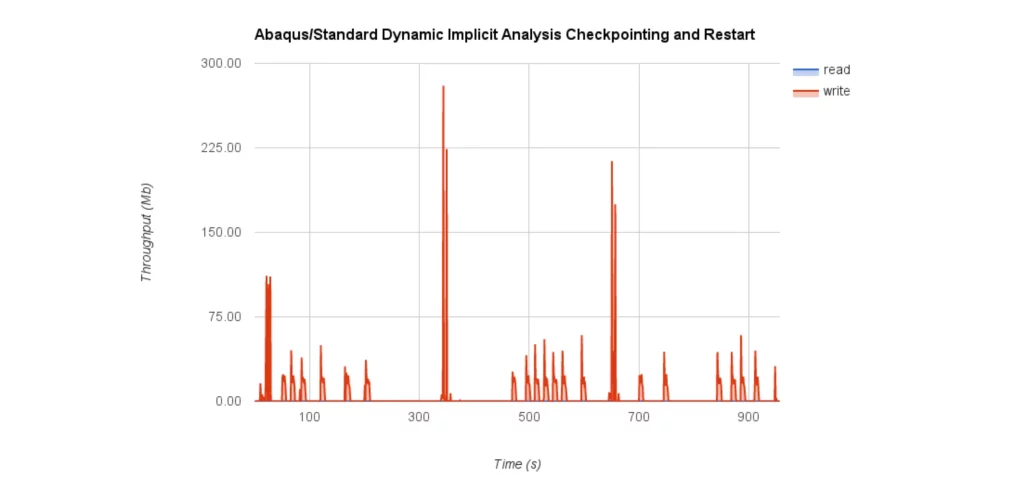
The benchmark results based on Abaqus/Standard Dynamic Implicit analysis show a low impact on the cluster file system, even with the highest frequency1.
Since Abaqus cannot run in close interaction with srun, Slurm’s native profiling tools are not useful. For that reason, the usage metrics have been collected with a custom version of dstat and plugins related to the cluster file system used (GPFS). In this case, the job has been re-queued every 300 seconds, except for the first one, which was delivered 320 seconds after the analysis started to run. The following figures show pictures of the cluster file system usage and the CPU load.
In this particular case, the impact of the restartjoin operation in terms of runtime is definitely a minor drawback (in many cases less than five seconds). However, in terms of IO, the restartjoin operation involves approximately 280MB of data, which represents the most expensive file system operation.

Please help us to improve the quality and the objectivity of these articles. We encourage you to send feedback to the authors and reviewers and suggest new ways to improve performance.
Authors: Jordi Blasco (Landcare Research @ NeSI / HPCNow!)
Reviewers: Gene Soudlenkov (Center for eResearch – University of Auckland) and Bart Verleye (Vrije Universiteit Brussel, Belgium)
Acknowledgement: We would like to gratefully and sincerely thank the valuable contribution of Angel Ashikov, who is a PhD student in Civil Engineering at The University of Auckland. He has been decisive in developing this workflow.
References: Simulia Abaqus 6.13 “Abaqus Analysis User’s Manual”.





